

Introduction
Think about what you were doing twenty minutes ago. Perhaps you were walking from class to class on your college campus and saying “hi” to friends as you saw them walk by. Maybe you were playing basketball at the gym and perfecting your three-pointer. Or maybe you were replying to some important emails on the very laptop you are looking at now. Regardless of what it was, unless you were asleep or vision impaired, I have to believe your eyes were open, and you were seeing the world around you. You watched that person smile as you walked by them on the way to class. You visualized the distance between yourself and the hoop as you shot that basketball. Perhaps you intensely focused on the screen while you may have replied to those emails. As humans, we take our ability to perceive for granted. Not only can we harness the light rays as they bounce off objects into our eyes, but we can also develop a deeper understanding of our world by making sense of visual data around us. Vision is a gift of evolution, and in the age of machine learning and advanced computing, it seems only right that the next step would be to provide computers the ability to perceive the world as well!
In the last decade, researchers in computer science have brought technology to the point where computers, for some specific tasks, can “see” bits and pieces of the world through the process of Deep Learning and Computer Vision. Now, obviously, they don’t perceive in the same way we as humans do because that would require the ability to consciously understand a lot about the nature of the universe and the human experience. However, they have become particularly impressive at doing specific visual tasks. These new skills have allowed professionals to let machines focus on tedious or monotonous parts of different processes. This allows people only to have to analyze the machine’s findings and they can now allocate more time doing the complex parts of their job. Some examples may include doctors using machines to detect cancerous tumors in CAT scans and other imagery, war generals allowing computers to track and detect enemy vehicles from sky imagery, machines replacing engineers to find anomalies in the production of manufactured products, and grocery stores installing computers to detect what a person takes out of the store so that they may be billed instantly. In order to truly understand how a computer with just imagery can accomplish these amazing feats, we must understand the basic structure upon which all modern machine learning algorithms are built upon – neural networks.
Deep Learning and Neural Networks
The basic building blocks for Computer Vision reside in a sector of Machine Learning called Deep Learning – the process of training a machine by feeding data into what is called a neural network (NN). Throughout the history of computers, there have been many attempts to create algorithms that could condense large amounts of data and information into real world findings and insights. But, to date, there has been no algorithm more successful than the neural network. Surprisingly enough, the brain inspired the basis on which these algorithms were designed. Every time you have a thought in your head, there are over 100 billion neurons firing off messages to one another which are known as action potentials. These are small electric pulses that propagate from one neuron to another, and the next pulse only “activates” if fed a specific amount of electrical and/or chemical energy [1]. Neurons are a lot more complex than that, but this is the general idea. Billions of these energy activations create all the thoughts, actions, and memories our neural intelligence provides us.
In 1958, a psychologist named Frank Rosenblatt studied the neurons in the brain when attempting to develop an algorithm for machine learning and created the perceptron [2]. These perceptrons have inputs, an output, and weights. A singular perceptron can be easily represented as a linear equation such as {w1x1 + w2x2 + b = o} where w1 and w2 are weights, x1 and x2 are inputs, b is the bias (bias is essentially the threshold or y-intercept of the equation), and o is the output. Below is an example of a single perceptron with an arbitrary amount of inputs and weights.
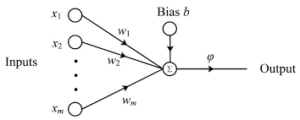
A Simple Perceptron [3] The perceptron above has an equation of i=1nxiwi + b = ![]() .
.
Obviously there doesn’t seem to be a lot of “intelligence” behind a linear equation that may represent the perceptron above. Anyone who has studied algebra in high school can see exactly what information is being abstracted here. But, you could imagine a whole network of these perceptrons, where the input layer passes information onto the hidden layers which pass the information to the final output layers. This allows information to be condensed and encoded into smaller and more optimized bits to use in machines that would not be possible without neural networks.
The magic really starts to happen when thousands, millions, or even billions of them are chained together in layers where inputs activate perceptrons and create outputs. If this could be seen visually it would look somewhat like a simulation of what neurons are doing in the brain. Just as neurons can “activate” other neurons within the brain, perceptrons can activate other perceptrons within a neural network. If the perceptron’s linear equation produces a value greater than zero, then it feeds a certain value of “energy” to the input of the next perceptron, and if it is less than zero it feeds a certain value for “no energy” to the input of the next perceptron. Depending on the activation function, energy can be represented with negative and positive values, probabilities between 0 and 1, or just 0 and 1 exclusively.
The “learning process” happens when an output is created from the layers, the machine is shown the solution to the problem, and it uses an algorithm known as backpropagation to adjust the weights and biases of all the neurons to more accurately predict the solution for that particular input the next time around. Do this thousands or even millions of times over with a broad range of inputs and you have a model that can generalize and produce an approximate solution for inputs that are similar to the training data, but that the model has never seen before. Below we have a network where the node on the left represents the input, the middle nodes are the hidden layers and the node on the right is the output. We can see the different activations or “energies” being propagated around the network by the different shades of red and blue.
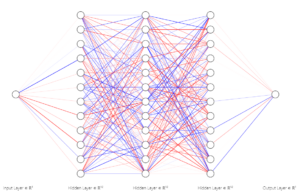
Activated Neural Net [4] The input node is on the far left, all of the nodes in the middle are part of the hidden layers, and the output node is on the far right. Blue edges represent negative values, red represents positive values, and the intensity represents the magnitude of these values.
Consider the following example of a simple neural network. With a series of inputs such as age, credit score, monthly income and debt, the model should be able to determine if that particular person should receive a loan from the bank. After feeding the network hundreds of thousands of past metrics of people who should and should not have received loans, and allowing it to adjust its parameters to better estimate what was deemed in the training as “the correct answers”, eventually the network will be able to predict, with high certainty, whether or not each newly presented person should receive a loan from the bank. This finding is astonishing! In fact, it has been proven mathematically that a neural network with only one layer between the inputs and outputs can approximate any continuous function. Of course, using only one layer for any problem would make the network slow and impractical to train, but nonetheless it is amazing that it is possible to solve any problem with a network this small.
Perception and Computer Vision
Now, how does this all relate to perception? Yeah, maybe a computer can use some numbers, devise solutions to any complex function and give a numerical output. But to actually detect cancer in images, find anomalies in computer chips, or even charge customers for groceries seems like an entirely different beast! I agree, that does seem like a stretch. But, the fascinating thing about images is that they can be broken down into pixels, which are nothing more than numerical values to represent a very specific color and brightness. And if we can treat all of the pixel values as inputs to a neural network, then the only difference in answering such a question like “Should they be approved for a loan?” or “Is there a cancerous tumor in this image?” is the fact that input numbers represent an image rather than data metrics. Thus, this means we care a lot about the location of the input pixels in the image, whereas there is no location for someone’s age or credit score. Location is an important factor in this case because pixels in proximity to each other are correlated in that they are likely to be part of the same object. The problem here is that the basic neural network structure that I discussed earlier does not take location into account at all.
A brilliant man named Yann LeCun devised a solution to this problem when he invented the Convolutional Neural Network (CNN). The CNN is a neural network that considers each pixel’s location and proximity to others when calculating the outputs of each layer. For example, if a network is trying to classify whether or not a specific pixel is part of a cancerous tumor, it is completely relevant to know what pixels are around that particular pixel and to use that information to determine whether a model can identify that pixel as cancerous. This remarkable new way of developing neural networks has allowed research labs and companies to take advantage of, and harness, the power of visual data and train networks to produce outputs in the form of object classifications and detections. Below is an example of how a Convolutional Neural Network might take an image and pass its information using what is called a convolution operation to keep data that is in a similar location together throughout the network until it is time to create an output or classification of the image.
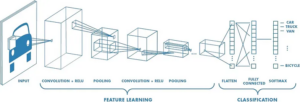
Convolutional Neural Net (CNN) [5] This is a diagram of a classification CNN that would inspect this image of a car and use convolutional layers to encode the image based on locality, and pooling layers that further encode the information into smaller pieces until the network has come up with a classification for the image either car, truck, bicycle etc.
The Power of Perception to Save Lives
Now that we have the technology to allow computers to take advantage of visual information, many tasks can be handed off to machines. In the field of health care, this evolution has been particularly astronomical. Now, we don’t need doctors to spend a lot of their time looking at CT scans, and we can use computer vision to quickly and more accurately predict whether a collection of cells is cancerous and we can do so at much earlier stages in the process. About 70% of lung cancers are detected in the later stages of the disease. At that point, it is much harder to treat and partly explains why there is only a 5 year survival rate [6]. With computer vision, we can now scan people in at-risk populations much more frequently, and the computer will be able to tell whether or not a collection of cells might be malignant without the strenuous hours that would otherwise be put on the doctor. They no longer have to spend the time analyzing all of the imagery. Instead, they can analyze work that the computer has already done and take a second look at the images flagged as suspicious.
Also, these cancer-detecting models can learn based on thousands if not millions of labeled examples, which is significantly more than any doctor could ever examine in his or her lifetime. These networks also often find patterns as to why a particular tumor might be cancerous that human doctors would never be able to. This is because computers are not limited to the 2D viewpoint our human eyes are limited to seeing the world through. Imagery can be analyzed in 3D with advanced networks, and even in 4D if scans of the same patient are available over different periods of time, giving neural networks an advantage because the computer can analyze this information all at once [7].
Google AI researchers created a machine learning model that detected lung cancer 5% more often than a group of six expert radiologists with an average of eight years of experience. It also reduced false alarms by 11%. This advancement in computer vision is a massive milestone in the field of medicine as it proves that in some cases, machines can evaluate imagery better than the best of humans.
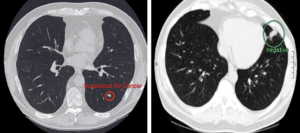
AI Cancer Detection [9] These are two images that have been analyzed by a Convolutional Neural Network. The one on the left was flagged as suspicious for lung cancer and the one on the right is flagged as negative for lung cancer.
In 2021, there were a whopping 350 machine learning medical devices approved by the FDA [8]. It is clear that allowing computers to be a second eye or opinion for doctors is a growing space and will save millions of lives in the future because of the efficiency and accuracy of these remarkable models. Even better, they are only going to get more advanced moving forward!
Conclusion
Perception is a gift. Without the ability to make sense of the data we can all see around us, we are lost. The fact that computers are slowly but surely able to take advantage of such a small fraction of the amount of imagery a human sees on a daily basis and turn it into amazing and possibly life saving results is outstanding! Humanity is evolving right before our eyes, and it’s not biological, but in fact it’s technological. We continue to find ways to teach computers to do tasks faster and more efficiently than anyone could. And with computers’ new ability to “see,” the evolution of computers, machine learning, and humanity just got much more interesting.
The next time you see that person walking down the hallway of your college campus, the next time you shoot that basketball and swish that three-pointer, or the next time you are analyzing your email strand and responding to email after email, just stop for a moment and appreciate what is going on behind the scenes in that head of yours. The amount of light your eyes are taking in and your brain is processing and turning into useful information within just those few examples is mind-blowing. Machine learning is in its infancy, and as it ages and evolves, maybe it will be able to take advantage of more visual information than any human could ever imagine “seeing” in their lifetime.
Work Cited
[1] https://qbi.uq.edu.au/brain-basics/brain/brain-physiology/action-potentials-and-synapses
[4]https://towardsdatascience.com/evolving-neural-networks-b24517bb3701
[6] https://www.nature.com/articles/d41586-020-03157-9
[7]https://www.medicalnewstoday.com/articles/325223#Model-outperformed-all-six-radiologists
[9]
https://venturebeat.com/ai/googles-lung-cancer-detection-ai-outperforms-6-human-radiologists/


