
Abstract
Much of what we do online is tracked. But how? There are two major web tracking techniques: cookies and browser fingerprinting. Cookies, which are data stored in a user’s browser by a website, come in the form of first-party and third-party cookies.First-party cookies, which compensate for weaknesses in how the internet is designed, are generally harmless, but third-party cookies are often abused by advertisers to track users across websites. However, both types of cookies are limited because users can block or delete them. Browser fingerprinting identifies users by the configuration of their browsers. Anti-fingerprinting tools make a user even easier to identify. Identity matching builds upon these two techniques to track users across devices.
Data collected by companies is typically anonymized by removing or encrypting names and demographic information, but this process can be reversed. As consumers grow increasingly privacy-conscious, major browsers are adding protections against third-party cookies and fingerprinting. This is good progress, but the field of web tracking is continuously evolving.
Caught in a Web
As a fiction writer, I’ve looked up a ton of weird stuff, such as “How fatal is a punctured lung?” and “Can you smash a concrete wall with a bone hammer?” Thankfully, the government didn’t break down my door, but I did get ads for surgical instruments for a week afterward.
How did that happen?
This isn’t a unique experience. 64% of American adults in 2019 reported seeing ads that seemed targeted to them. Broadly, 91% of Americans believe companies are tracking their online activity, and only 19% feel they have control over their data [1]. Understanding how companies track you will help you protect your information, have realistic expectations for your online privacy, and, crucially, recognize disinformation.
Web tracking techniques used by companies can usually be categorized as stateful or stateless. The former depends on storing information on a user’s device, whereas the latter does not. The most notable stateful technique is cookies; the most notable stateless technique is fingerprinting [2]. However, identity matching, which tracks users across devices, does not fit into either category.
Hungry for Information
The innocently-named cookie is probably the most infamous web tracking technique. However, it also makes the internet easier to use. Think back to all the times you’ve logged into a website, closed it, then opened it again later and found that you were still logged in. Convenient, right? That’s all thanks to cookies.
Cookies are part of the Hypertext Transfer Protocol (HTTP), which defines a “language” that browsers and websites use to communicate with each other (hence why web addresses often start with “http://”). HTTP describes everything we do online as a client and server talking to each other [3]. Browsers (e.g. Chrome) are clients: to open a website, a browser must talk to the website’s server. Formally, the client is said to make requests to the server: for example, to get a webpage located at a certain URL, or to submit a form. The server receives this request, processes it, and answers with a response [3]. This request-response pattern means the client must initiate contact; the server only reacts to the client’s demands.
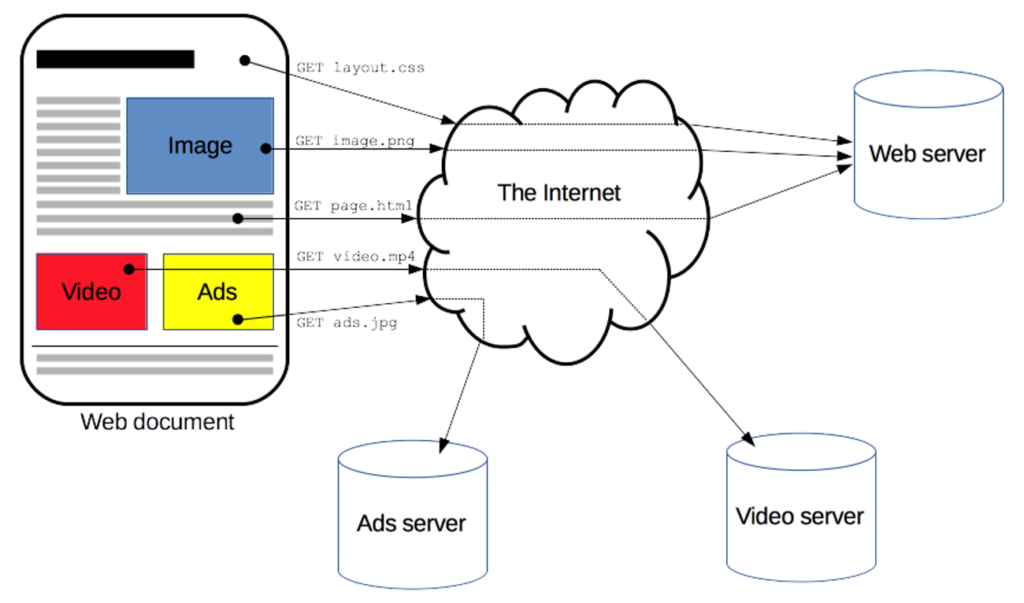
The HTTP protocol is also stateless: that is, it has no “memory.” The hundredth time you visit a website isn’t treated any differently than the first time [3]. This can be frustrating for users: accidentally closing Amazon and losing everything in your cart, for instance, or enabling dark mode on Reddit, closing it, and then blinding yourself when you open it up again at 2 AM.
This is where cookies come in. The first time you open a website, its server may send some data for your browser to store. For example:
logged_in_user=none, dark_mode=false
If you log in or enable dark mode (or both), the website tells your browser to update this data:
logged_in_user=Alice, dark_mode=true
This data is a cookie [4]. If you close the site and open it again later, the browser can pass along this cookie when it requests the website content from the server. That lets the server go, “Aha! I’ve seen you before!” and personalize your experience accordingly: perhaps displaying “Welcome back, Alice!” and enabling dark mode (thus sparing your eyes).
How Do Different Cookies Track You?
Note that a website can record user activity without cookies. Actions such as clicking a button or link can trigger code, which means it’s simple to, say, count how many times a button was clicked [5]. But what if the website wants to know how many times Alice clicked the button, versus how many times Bob clicked the button?
The solution: when the button is clicked, the browser reads its cookies and sees that “logged_in_user” has a value of “Alice.” Now the browser can tell the website server, “Alice clicked this button.” Over time, as the website server continues collecting data, it can build a profile of each user: their likes and dislikes, behavioral patterns, and more.
In this example, the website creates cookies when a user visits it, and only accesses the cookies that it created itself (not cookies created by your visits to other websites). As a result, the website only tracks what you do while you’re on that site. This type of cookie is called a first-party cookie and is usually used by individual websites to personalize your experience [3].
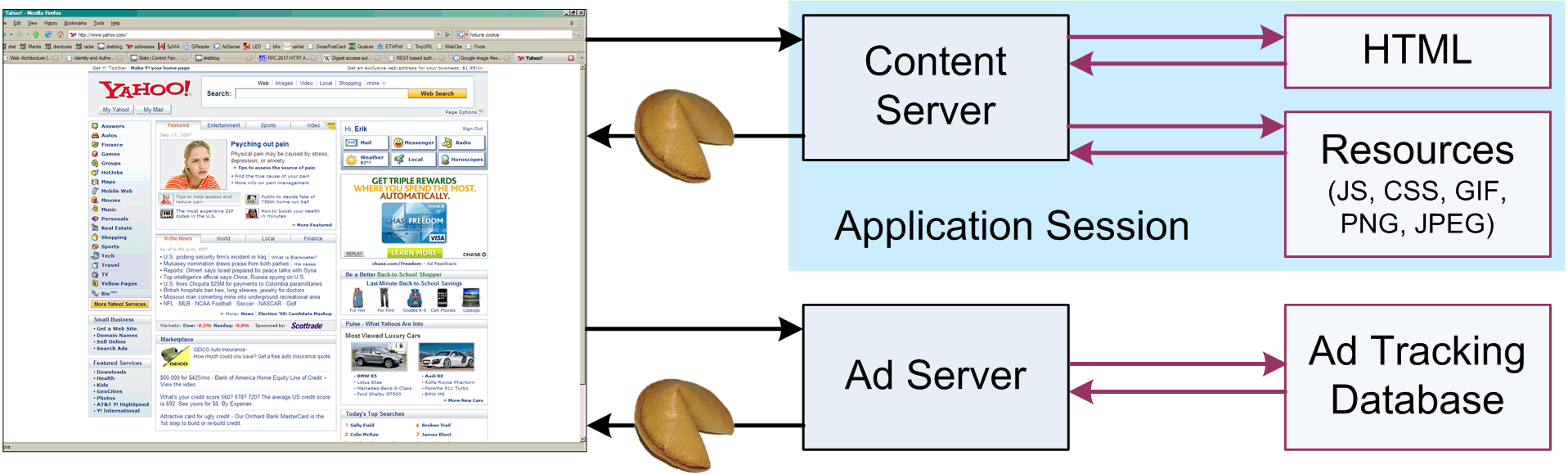
Third-party cookies, on the other hand, allow advertisers to track you across multiple websites. To illustrate, consider an advertising company called AdTech, which provides ads for Website A.
When you visit Website A, you talk to their server to load the page, so you would expect to receive a cookie from them. But what you might not realize is that you’ve also received a cookie from a third party, AdTech. How?
Because the ads on Website A are actually stored on AdTech’s server, your browser needs to talk to AdTech’s server to display them. This creates an opportunity for AdTech to give you a cookie or read any cookies it gave you previously. The cookie sends your activity on Website A back to AdTech. If you leave Website A and go to Website B, on which AdTech also serves ads, then AdTech will be able to record your activity on Website B as well [2].
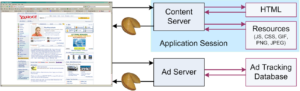
Fortunately, cookies have two weaknesses. First: because cookies are stored by your browser, they are virtually impossible to access from another device, or even a different browser on the same device. Second: most browsers let privacy-conscious users block or delete cookies in their settings. However, fingerprinting does not have this second weakness and is far more difficult to protect against.
Your Digital Fingerprint
Websites can access information about how a browser is configured: for example, the operating system, language, even timezone and screen resolution [7]. This information is typically used to enhance the user experience: for example, translating content or disabling features that aren’t compatible with the browser. However, because different users have different browser configurations, it’s possible to use this information to generate an identifying fingerprint [7].
Some privacy tools try to hide this information using a technique called user-agent-spoofing, in which a browser “pretends” to be another browser. For example, say a website only allows Chrome users to visit it. However, a Safari user using a user-agent-spoofing tool could pretend to be on Chrome and gain access to the website [8]. Ironically, these tools can make browsers more vulnerable to fingerprinting because they are not widely used: the few users who use these tools can be identified by their usage (what a tongue-twister!) [7].
That said, fingerprinting is somewhat unreliable. First, there is no guarantee fingerprints are globally unique. Second, fingerprints change over time as a user updates their browser, installs plugins, adds fonts, and more [7]. And what if someone owns two phones, a laptop, and a tablet, each with their own fingerprint? How can you track one person across multiple devices?
Where’s Waldo Across Devices
With the majority of Americans owning at least two digital devices, identity matching—linking activity across devices to a single user—is incredibly valuable for advertisers [9]. Identity matching is often offered as a service by specialized companies, who maintain large databases of people and perform matches by searching through these databases [10].
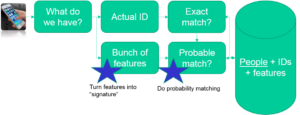
Figure 3. How identity matching generally works. On the right is a database. The top path is deterministic; the bottom is probabilistic [10]
But what happens when a deterministic match isn’t possible? Maybe all IdentifyMe knows about you is your geographic location. Or maybe they’ve never seen your email before. Either way, they are presented with an unrecognized user.
To rectify this, IdentifyMe runs an algorithm to find the most similar user in their database (fingerprints may be one of the data points used to compute similarity). Then, IdentifyMe will hypothesize that these two users are the same. This is a probabilistic match [10].
As another example: you visit a grocery store’s website on your laptop and check if they have any ice cream. IdentifyMe has never seen you before, so they record your activity, along with your location and the current time, under Laptop X.
An hour later, you type “nutrition content of ice cream” into your phone’s search engine. IdentifyMe records this under Phone Y and looks through its database. Two similar searches, originating from the same location at roughly the same time? That’s probably the same user. Now IdentifyMe can say, with reasonable confidence, that you own both Laptop X and Phone Y and really like ice cream [11]. They may sell these insights to an advertising company—so when you return to your laptop, expect to see ads for low-calorie ice cream.
Both deterministic and probabilistic matching are difficult to guard against. Many websites and apps restrict their functionality unless you log in [12]. The latter is powered by data generated by your daily use of the internet: logins, browsing and search history, social media posts, and more [11]. The only way to escape, it seems, is to unplug.
Slap Some Groucho Glasses on It
Given all this data companies can collect about you, does that mean they know who you are, where you live, and your deepest, darkest secrets?
The answer is complicated. Before sharing their data with others, companies often anonymize it by removing or encrypting names and demographic information [13]. While all of your activity is still associated as originating from a specific user, there is no connection between that user and your real-world identity—at least, in theory.
In practice, not so much. Researchers in 2009 developed an algorithm to link anonymized social network data back to the originating users, simply by analyzing the data. When tested on Twitter, the researchers were able to confidently re-identify a third of users who had both Twitter and Flickr accounts [13]. While this is a fraction of all Twitter users, these results show anonymization is by no means foolproof, and that users should take a good look at a company’s privacy policy before sharing any sensitive information.
Whack-a-Web Tracking Technique
The truth is, you can’t have complete privacy online. As more people become aware of a tracking technique, a countermeasure is bound to emerge, but new techniques are constantly being developed. For example, “zombie cookies” can regenerate themselves after being deleted and have been used by companies like Google and Facebook. We know about this not because the companies involved disclosed it, but because an independent researcher discovered it [14]. In light of this, it’s reasonable to assume there are tracking techniques out there that we don’t know about—and therefore can’t protect ourselves from.
Additionally, a study published in 2011 found that after the European Union passed privacy regulations which limited the ability of companies to track users on the internet, the effectiveness of online ads dropped about 65% [15]. However, intrusive or otherwise attention-grabbing ads were not significantly affected. Thus, if tracking is further limited, advertisers may compensate with flashier ads [15]. This is a tradeoff not all users may want to make.
That said, in 2018, Chrome began blocking annoying ads, as defined by the standards published by the Coalition for Better Ads: for example, pop-ups [16]. Microsoft is also a Coalition member, suggesting Edge might add a similar feature [17]. If more browsers follow suit and enforce compliance with the Better Ads Standards, it will significantly improve the experiences of users. Additionally, because consumers are increasingly demanding privacy, a browser that lacks privacy features risks losing market share to safer alternatives. This pressure has moved major browsers including Chrome, Safari, and Firefox to block third-party cookies by default or phase out support entirely. They are also developing protections against fingerprinting [18].
Although the internet is unlikely to ever be truly private, there are steps you can take to protect yourself against the more common tracking methods. Get a browser with the latest privacy features. Watch what information you share online. And most importantly, stay informed.
References
[1] B. Auxier, L. Raine, M. Anderson, A. Perrin, M. Kumar, and E. Turner, “Americans and Privacy: Concerned, Confused and Feeling Lack of Control Over Their Personal Information,” Pew Research Center, Nov. 15, 2019. [Online]. Available: https://www.pewresearch.org/internet/2019/11/15/americans-and-privacy-concerned-confused-and-feeling-lack-of-control-over-their-personal-information/. [Accessed Feb. 3, 2020].
[2] I. Sanchez-Rola, X. Ugarte-Pedrero, I. Santos, and P. G. Bringas, “The web is watching you: A comprehensive review of web-tracking techniques and countermeasures,” Logic Journal of the IGPL, vol. 25, no. 1, Aug, 2016. [Online serial]. Available: https://academic.oup.com/jigpal/article/25/1/18/2842096#53212637. [Accessed Feb. 2, 2020].
[3] Mozilla, “An overview of HTTP,” MDN Web Docs, 2019. [Online]. Available: https://developer.mozilla.org/en-US/docs/Web/HTTP/Overview. [Accessed Feb. 2, 2020].
[4] Mozilla, “HTTP cookies,” MDN Web Docs, 2019. [Online]. Available: https://developer.mozilla.org/en-US/docs/Web/HTTP/Cookies. [Accessed Feb. 2, 2020].
[5] Refsnes Data, “onclick Event,” W3Schools. [Online]. Available: https://www.w3schools.com/jsref/event_onclick.asp. [Accessed Feb. 2, 2020].
[6] E. Wilde and P. Kakirwar, “third-party-cookie.png,” dret.net, 2010. [Online]. Available: http://dret.net/lectures/web-fall10/img/third-party-cookie.png. [Accessed Feb. 2, 2020].
[7] P. Eckersley, “How Unique is Your Web Browser?” in Privacy Enhancing Technologies. Berlin, Heidelberg: Springer Berlin Heidelberg, 2010. [E-book]. Available: https://link.springer.com/chapter/10.1007/978-3-642-14527-8_1. [Accessed Feb. 2, 2020].
[8] N. Nikiforakis, A. Kapravelos, W. Joosen, C. Kruegel, F. Piessens, and G. Vigna, “Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting,” IEEE Symposium on Security & Privacy, 2013. [Online serial]. Available: https://ieeexplore.ieee.org/document/6547132. [Accessed Feb. 2, 2020].
[9] M. Anderson, “Smartphone, computer or tablet? 36% of Americans own all three,” Pew Research Center, Nov. 25, 2015. [Online]. Available: https://www.pewresearch.org/fact-tank/2015/11/25/device-ownership/. [Accessed Apr. 5, 2020].
[10] M. Kihn, “How Cross-Device Identity Matching Works (part 1),” Gartner, Aug. 9, 2016. [Online]. Available: https://blogs.gartner.com/martin-kihn/how-cross-device-identity-matching-works-part-1/. [Accessed Feb. 5, 2020].
[11] A. Tanner, “How Ads Follow You from Phone to Desktop to Tablet,” MIT Technology Review, Jul. 1, 2015. [Online]. Available: https://www.technologyreview.com/s/538731/how-ads-follow-you-from-phone-to-desktop-to-tablet/. [Accessed Feb. 2, 2020].
[12] M. Zawadziński, “Deterministic and Probabilistic Matching: How Do They Work?” Clearcode, Dec. 15, 2016. [Online]. Available: https://clearcode.cc/blog/deterministic-probabilistic-matching/. [Accessed Feb. 4, 2020].
[13] A. Narayanan and V. Shmatikov, “De-anonymizing Social Networks,” IEEE Symposium on Security & Privacy, 2009. [Online serial]. Available: https://ieeexplore.ieee.org/document/5207644. [Accessed Feb. 2, 2020].
[14] J. Angwin and M. Tigas, “Zombie Cookie: The Tracking Cookie That You Can’t Kill,” ProPublica, Jan. 14, 2015. [Online]. Available: https://www.propublica.org/article/zombie-cookie-the-tracking-cookie-that-you-cant-kill. [Accessed Feb. 4, 2020].
[15] A. Goldfarb and C. E. Tucker, “Online advertising, behavioral targeting, and privacy,” Communications of the ACM, vol. 54, no. 5, May, 2011. [Online serial]. Available: https://dl.acm.org/doi/10.1145/1941487.1941498. [Accessed Feb. 2, 2020].
[16] Google, “Improving user experience with the Better Ads Standards,” Google Ad Manager. [Online]. Available: https://admanager.google.com/home/resources/feature-brief-better-ads-standards/. [Accessed Apr. 19, 2020].
[17] N. Ives, “As Microsoft Joins Coalition for Better Ads, Blocking by Browsers Looks Set to Spread,” Ad Age, Sept. 20, 2017. [Online]. Available: https://adage.com/article/digital/microsoft-joins-coalition-ads/310530. [Accessed Apr. 17, 2020].
[18] W. Davis, “Ad Industry Blasts Google’s Cookie-Blocking Plan,” MediaPost, Jan. 16, 2020. [Online]. Available: https://www.mediapost.com/publications/article/345795/ad-industry-blasts-googles-cookie-blocking-plan.html. [Accessed Feb. 2, 2020].



{kind=link}