

Abstract
Natural language processing (NLP) techniques help artificially intelligent computers understand
and answer the questions that humans ask. Though NLP in artificial intelligence was popularized in everyday devices like Apple’s Siri and Amazon’s Alexa, we can trace many of the techniques and methods used today back to Watson, the Jeopardy! robot. Growing NLP capabilities drive innovation in technology that directly affects society and the way that information is searched for and consumed and we are beginning to explore how it can affect certain industries like healthcare.
Introduction
When most people have a question, they either ask someone for the answer or look it up on
Google. However, developments in Natural Language Processing (NLP) allow users to directly ask a computer for a quick answer. If you’re a smartphone owner, you’ve probably already tried this. Whether you used Apple’s Siri, Microsoft’s Cortana, or Amazon’s Alexa, all of these AI’s can understand and respond to your speech. The intelligence of these machines shows that computers are powerful question answering (QA) tools.
When answering a question, a computer must understand what is being asked before trying to find an answer to the question. Although humans can understand and answer complex questions with little to no effort, it is difficult for computers to understand even the simplest of questions without the use of NLP. Language processing abilities are necessary to both decipher questions being asked and to glean knowledge from online sources.
Basics of Natural Language Processing
Human language, whether verbal or written, is often not precise. Sentences vary widely and
contain ambiguity, making it difficult for computers to understand. Information is also often
unstructured, meaning it is not broken down into clear computer-friendly pieces of information.
Therefore, a computer must be taught how to understand natural language.
Natural Language Processing uses reasoning by analogy to understand language [1]. It finds
relationships between parts of the text – from words and phrases to paragraphs and entire
documents – and relates these patterns to those that it has previously encountered [2]. NLP-based devices often use many techniques simultaneously to understand natural language. To better understand NLP, we will explore three basic techniques used to break down language, although many other techniques exist.
One fundamental technique of NLP is Parts-Of-Speech Tagging (POST). It takes a piece of text,
called a corpus, and associates each word with a syntactic tag, such as “adjective”, “adverb”,
“noun”, and “verb” to name a few. Tagging is based on knowledge of the definition of a word
and the context given by the adjacent words, phrases, sentences, or paragraphs [1].
POST starts by narrowing down the possible tags for a word based on its definitions. For
example, the word “fly” could be a noun or a verb depending on the context. We know that
adjectives usually come before nouns and adverbs usually follow verbs. If we say “big fly”, the
word “fly” would be tagged as a noun modified by the adjective “big”. If we say “fly high”, it
would be tagged as a verb. Some expressions are more complex than others and require more
context than the preceding or following words, leading to more complex POST techniques.

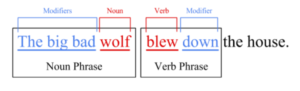
Another technique is shallow parsing, commonly known as chunking. Chunking takes the
corpus, tagged with parts of speech, and breaks it up into sections. This means it combines a
noun with all of its modifier words to make a noun phrase. For example, “the big bad wolf” is a
noun phrase with three modifier words, “the big bad”, and a noun, “wolf”. The same could be
done for verbs and other parts of speech to section off an entire sentence. Chunking is
particularly useful for Named Entity Recognition (NER) which identifies places, names, or other
entities within sentences [1].
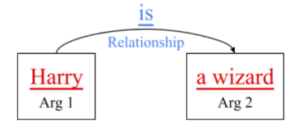
Lastly, Semantic Role Labeling (SRL) looks at predicates to determine the relationship between
a verb’s arguments [1]. The computer knows the rule that the word “is” equates the first argument to the second argument. It compares a similar phrase to this rule and forms an analogy to understand the phrase. For example, the phrase “Harry is a wizard” relates the first argument “Harry” to the second argument “a wizard” using the word “is”. Building a library of word relationships through SRL is a fundamental tool in many NLP toolboxes.
The Ultimate Question Answering System
After its chess-playing robot Deep Blue beat world chess champion Garry Kasparov in 1997,
IBM started looking for greater challenges in artificial intelligence. In 2005, IBM found their
challenge in the complexity of the trivia game Jeopardy! and created Watson, supercomputer that relies heavily on NLP to understand questions and gather knowledge to generate answers [3].
Jeopardy! contestants are asked a variety of general knowledge quiz questions from puns and idioms to factoids and puzzles. Quiz questions are given as clues and answers must be given in the form of a question [4]. A sample clue would be “This number, one of the first 20, uses only one vowel (4 times!).” to which a contestant would answer “What is seventeen?” To a human, answering this is a trivial task, but it is not so easy for a computer.
Watson interprets questions much like humans do by looking for keywords and relationships that indicate the kind of question that is being asked. It does this by breaking down the clues using hundreds of NLP techniques, including the three basic methods of POST, chunking, and SRL [3] [5]. These methods take the unstructured information contained in the clue and translate it to structured data that Watson is able to use.
To figure out the type of question being asked, Watson categorizes each question based on its
previous knowledge. To illustrate this, let’s consider how Google categorizes search inquiries.
For instance, if you use Google to search for “Japanese restaurants,” Google would recognize the inquiry as a search for nearby Japanese restaurants and would pull up a map of restaurants as the first result, not an article about Japanese restaurants. Google answers in this way because it notices the pattern that the first result people usually click on when searching “restaurants” is for a restaurant suggestion and not an informational article. This use of previous experience to understand natural language is what makes Google search results so relevant [6].
Similarly, Watson was fed a bank of question and answer pairs from previous Jeopardy! games
to learn from. From that bank of questions, Watson classifies each unique type of question based on the patterns it has noticed and develops its own rules for categorizing these questions. It also associates a specific type of answer to each category so that it won’t give a factoid as the
answer to an idiom question [5].
The core of Watson’s question–answering capabilities lies in its ability to gather and understand
immense amounts of information that are presented in natural human language, especially
information that is generally unstructured and meant to be communicated between humans.
Watson uses NLP to extract nuggets of information from millions of books, dictionaries,
encyclopedias, news articles, and other texts available on the internet. It stores this information
for later use in Jeopardy! and for answering general questions [5]. Watson’s ability to understand and memorize unfathomable amounts of information makes it one of the most powerful AI’s to date.
The creation of Watson has undoubtedly ushered in a new era in artificial intelligence and has
brought natural question-answering machines one step closer to being a part of our everyday lives. However, the technology is still far from perfect and has a long way to go before being accessible at a consumer level.
It’s Not All Fun And Games: Real World Applications
The incredible language processing power pioneered by Watson has opened the doors to many
new and exciting technologies. One of these NLP-based technologies takes the form of sentiment analysis to support financial decision making. Sentiment analysis identifies and summarizes the opinions presented in natural language texts such as news, blogs, and social media. Often, these subjective sources provide information that raw numerical data does not. For instance, a sentiment analysis may be performed on customer reviews of a product found on a blog or forum. The analysis looks for words that indicate how customers feel about the product. Words such as “great” and “terrific” indicate that a customer is satisfied. Then, if the sentiment summary indicates that most customers are satisfied with the product, the appropriate financial investments will be made.
A paper published by the Association for the Advancement of Artificial Intelligence (AAAI) in
2010 describes a stock trading strategy that uses linguistic media information to gain an edge over purely data based strategies [7] [8]. The strategy gathers information from news, blogs, and Twitter posts worldwide and runs sentiment analysis on them. Sentiment summaries are then used to predict growing or decaying stock trends, which urge increased or decreased investment respectively. A simulation of this trading strategy over four years of data from the New York Stock Exchange generated steady returns on investments.
Another application of NLP systems is called a Clinical Decision Support System (CDSS),
which is designed to help professionals in the healthcare sector make clinical decisions [9] [10].
A system like this is not only useful for immediate feedback on a patient’s health, but also for
continuous monitoring of their recovery progress. The necessity of such a system is apparent
when considering the amount of information contained in an electronic health record (EHR) [9]. A person’s medical history may be extensive and contain too much information for a human to process quickly and thoroughly. This task could be time-consuming for humans, who are also generally susceptible to making errors. A computerized system would remove the human component, making data processing and analysis more efficient and accurate. However, since EHRs are mainly available in free-text form, a CDSS would be impossible without language processing capabilities [9]. NLP is used to extract information from the EHRs and to gather medical knowledge from books and other sources. Clearly, NLP plays an important role in making more powerful computer systems possible, systems that will impact society in increasingly revolutionary ways.
Conclusion
As NLP becomes more advanced, we can expect it to become even further integrated into our everyday lives. Even today, daily tasks like setting alarms and making restaurant reservations are automated, relying entirely on NLP of the user’s language and turning it into a command for the computer. While thus far NLP has been a useful tool to remove tedious tasks from our busy schedules, at what point are the decisions too important for a computer to make without human oversight? When computers begin to take on more complex tasks as a result of NLP we should be wary of not taking moral responsibility for the actions that the computers execute at our commands.
Suggested Activity:
Sentiment analyzer using Python Natural Language Toolkit (NLTK). Try inputting a news article, product review, or movie review to analyze! Link here: http://text-processing.com/demo/sentiment/
Suggested Further Reading:
● IBM Watson’s Page
● Natural Language Processing Resources For Implementation
● Sentiment Analysis Resources
Acronyms:
● NLP: Natural Language Processing
● AI: Artificial Intelligence
● QA: Question Answering
● POST: Parts-Of-Speech Tagging
● NER: Named Entity Recognition
● SRL: Semantic Role Labeling
● AAAI: Association for the Advancement of Artificial Intelligence
● CDSS: Clinical Decision Support System
● EHR: Electronic Health Record
References:
[1] R. Collobert , J. Weston , L. Bottou , M. Karlen , K. Kavukcuoglu , P. Kuksa, “Natural
Language Processing (Almost) from Scratch”, The Journal of Machine Learning Research, 12,
p.2493-2537, 2/1/2011
[2] M. Kiser, “Introduction to Natural Language Processing (NLP) 2016 – Algorithmia”,
Algorithmia, 2016. [Online]. Available: http://blog.algorithmia.com/introduction-natural-language-processing-nlp/. [Accessed: 31- Aug-
2016].
[3] D. Ferrucci, E. Brown, J. Chu-Carroll, J. Fan, D. Gondek, A. Kalyanpur, A. Lally, J.
Murdock, E. Nyberg, J. Prager, N. Schlaefer and C. Welty, “The AI Behind Watson — The
Technical Article”, Aaai.org, 2016. [Online]. Available:
http://www.aaai.org/Magazine/Watson/watson.php. [Accessed: 12- Sep- 2016].
[4] “Jeopardy! – Game Shows Wiki – Wikia”, Gameshows.wikia.com, 2016. [Online]. Available:
http://gameshows.wikia.com/wiki/Jeopardy!. [Accessed: 12- Sep- 2016].
[5] G. Goth, “Deep or Shallow, NLP Is Breaking Out”, Cacm.acm.org, 2016. [Online].
Available:
http://cacm.acm.org/magazines/2016/3/198856-deep-or-shallow-nlp-is-breaking-out/fulltext.
[Accessed: 31- Aug- 2016].
[6] D. Sullivan, “How Google Instant’s Autocomplete Suggestions Work”, Search Engine Land,
2011. [Online]. Available:
http://searchengineland.com/how-google-instant-autocomplete-suggestions-work-62592.
[Accessed: 12- Sep- 2016].
[7] W. Zhang and S. Skiena, “Trading Strategies to Exploit Blog and News Sentiment”, in Fourth
International AAAI Conference on Weblogs and Social Media, Stony Brook, NY, 2016.
[8] K. Church and L. Rau, Commercial Applications of Natural Language Processing, 1st ed.
2016.
[9] W. Chapman, W. Bridewell, P. Hanbury, G. Cooper and B. Buchanan, “A Simple Algorithm
for Identifying Negated Findings and Diseases in Discharge Summaries”, Journal of Biomedical
Informatics, vol. 34, no. 5, pp. 301-310, 2001.
[10] D. Demner-Fushman, W. Chapman and C. McDonald, “What can natural language
processing do for clinical decision support?”, Journal of Biomedical Informatics, vol. 42, no. 5,
pp. 760-772, 2009.



{kind=link}