
Written by: Vicky Hui
Competitive AI systems beat the best human players in chess, “Go,” checkers, and poker [1]. Over the last decade, innovation in AI learning has enabled computers to navigate more complex and chaotic problems in the real world, through soft-coded systems and reinforcement learning. Most recently, this has been exhibited in the form of the video game Dota 2, involving a coordination model that is designed to work like a human brain, optimizing strategy through systematic training.
AI in Video Games
During the largest eSports tournament in 2017 at “The International,” the gaming community witnessed a landmark achievement in Artificial Intelligence (AI) advancement. During a one-on-one show-match for the MOBA (Multiplayer Online Battle Arena) video game Dota 2, a professional player went head-to-head with a bot developed by OpenAI, a non-profit research company that works on AI and robotics. To everyone’s surprise, the player was swiftly dismantled in two games with what seemed to be the bot’s superior reflexes, gameplay, tactics, and profound understanding of the game’s fundamental mechanics. How did the bot manage to develop such nuanced strategic tools to outplay a professional human player?

Figure 1. Match between the OpenAI bot and a professional Dota 2 player [11].
Journey of Human vs. AI
In the past, AI played against professional players in chess, “Go,” poker, and checkers. For chess, IBM’s Deep Blue beat the world’s best players by training over a large data set, teaching the AI bot all of the possible outcomes to a particular move. This was largely successful because chess is restricted to a set of defined rules between two players. So what would happen in a fast-paced multiplayer game like Dota 2, where computers would be required to collaborate in order to navigate unpredictable circumstances and use real-time strategies with each move vastly affecting the outcome? According to Jakob Foerster, a computer scientist at the University of Oxford who works on Starcraft II, another real-time strategy game, this requires “strategic reasoning, where [the computer is] understanding the incentives of others” [1].
Dota 2 (Dota) is a real-time, team-based game between two teams of five players. The objective is to destroy the opposing team’s structure while defending your own, collecting resources to strengthen your skills and fight opponents along the way. This may seem relatively straightforward, but it involves a combination of strategy, mechanical skill, coordination and team-work. On top of making judgement calls, players in Dota 2 need to develop team coordination. Unlike chess, where you have a full minute to decide your next move, Dota 2 continues in real-time, where every millisecond counts, involving a great deal of adaptation and awareness to your environment to make quick, successful decisions. In addition, the teamwork component of playing five-on-five makes for more exciting and dynamic scenarios. While a move in “Go” has a few hundred options at most, the action in Dota 2 is constant and three-dimensional, with each move allowing for thousands of options; players can choose where to go, which spell to cast, and where to aim it. The game’s level of freedom, randomness, and the player’s blindness to what is out of their limited range of vision, makes gameplay less predictable — a considerable challenge for developing effective AI. Therefore, compared to board games with a finite range of possible moves, Dota 2 is more comparable to the “messiness and continuous nature of the real world” [2].
AI developed for chess and “Go” made use of search trees, which analyzed the “branching possibilities far into the future” [1]. In contrast, forecasts for Dota 2 are less clear, increasing the difficulty of accurate predicting outcomes. In addition to the complex nature of teamwork, which allows a greater magnitude and range of possible actions, players do not have perfect information due to limited map vision. Players are unable to see their opponents at all times, meaning that teams have to constantly make decisions with incomplete information through a communication channel.
OpenAI utilizes neural networks to learn and apply gameplay. Neural networks described here work very similarly as our brain, by “[strengthening] connections between small computing elements in response to feedback” [1]. Supervised learning is a method commonly used in machine learning applications, which requires an input into the neural network model and a known output that the model can produce. To apply supervised learning to train AI neural networks to play a relatively simple game like Pong, you would create a data set from a human player, logging the frames that the player sees on screen (the input) and the actions they take, pushing the up or down arrow in response to those frames (the output). Once you feed the input frames through a simple neural network, it will either select the up or down action by training with the data set of human gameplay. While the neural network can successfully learn to replicate human gameplay, this approach has significant disadvantages.
AI neural network training requires an initial data set to train with, which is not always accessible. If you train a neural network to simply imitate the actions of the human player, then the agent will never be able to beat the human player. To overcome this challenge, OpenAI uses the method of reinforcement learning, requiring a bot to learn and play the game entirely by itself by solving tasks in dynamic, changing environments. The bot learns to recognize intermediate rewards and learn from short- term goals that bring it closer to winning. By training repeatedly, the system tries different moves, establishing connections when they perform well, consequently reinforcing and reproducing rewardable actions in the game. Ultimately, OpenAI’s goal, in developing systems which can solve video games, is to apply them to more general, real life applications outside of just games, as neural networks in humans can be used to solve problems through adaptive learning.
Reinforcement Learning
OpenAI utilizes Reinforcement Learning (RL), which is an approach that allows the computer to figure out optimal actions through repeated trial and experimentation, rather than by program. It learns through a natural curriculum of self-play, exploring the environment in order to adopt basic strategies and alter its instructions each round. This is the same method that enabled DeepMind’s AlphaGo to master the board game Go, and beat one of the best human players in the world in a high-profile match in 2017 [2]. Within the first few games, the bot will walk around the map aimlessly; however, after several hours of training, it will learn basic concepts, and the system will learn to favor behaviors or actions that lead to rewards. The bot will repeat this, training against itself in 80% of games, and training against its past selves in the other 20%, to avoid “strategy collapse” [4]. It does so with the goal of maximizing the sum of future rewards, responding to a reward system consisting of aggregated metrics in the game. As presented in Figure 3, the bot will consider the cost of an action against its reward. More specifically, the measure of resources used performing an action will be compared to the magnitude of the reward. It will compare this action to all other possible actions that can be achieved with the same cost, and choose the action that gives the highest reward. Thus, it will generate a set of responses that will optimize its win-condition given any scenario presented [4]. In other words, rather than hard-coding the bot, AI trains by playing games against itself— similar to the way most players learn through persistent practice. The neural network governing the bot’s decision-making will be adjusted each time, allowing it to develop a level of finesse and efficiency that it deems optimal over time.
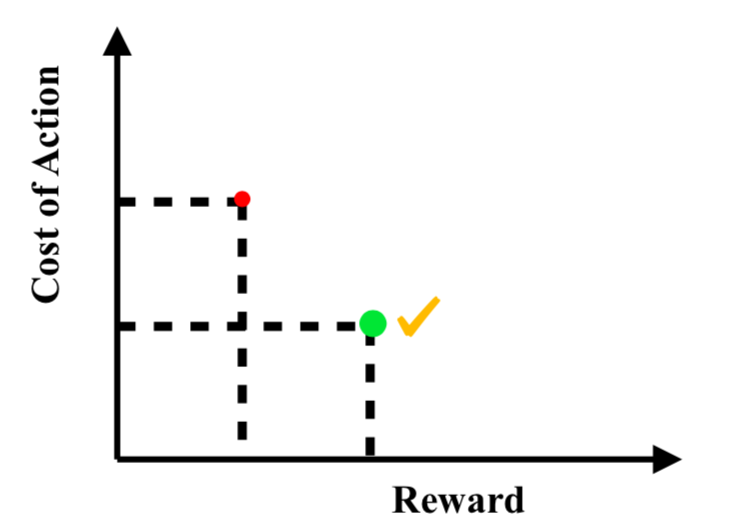
Figure 3. AI bots learn to optimize their actions by selecting an paths that minimize cost and maximize reward.
Beyond its application in video games, this method of reinforced learning has the potential to improve computer intelligence in self-driving cars, teach robots to grasp objects it has not seen before, and figure out the optimal configuration for the equipment in a data center [5]. It is particularly important to develop for automated driving, because it enables a “good sequence of decisions”, whereas encoding those decisions in advance would take longer for programmers [5].
OpenAI 5
In the International 7 Dota 2 Tournament of 2017, the OpenAI bot managed to beat the best human players in one-on-one games (one bot versus one human). At the 2018 International Tournament, the full five-on-five team matches proved to be a much greater challenge as OpenAI upscaled the system to five neural networks to match against five top-performing professionals. The professionals had dedicated years of training together to compete for the largest prize pools in the eSports scene, while the OpenAI Bots started from scratch, learning to play the game through self-play, at a rate of 180 years of gameplay per day. During training, the bot played millions games against different versions of itself and learned recognition strategies.
While OpenAI 5 surpassed previous benchmarks of defeating amateur and semi-professional teams, it lost in two close games against professional teams at The International 8, demonstrating mechanical gaps and restrictions to the AI’s play-style compared to professional players. The OpenAI team indicated that they were optimistic that through reinforcement learning, the method could “yield long-term planning with a large but achievable scale” through further advances [2].
Through video games, OpenAI has shown how the implementation of a coordination model with soft-coding in a system that learns and works like a human brain shows enormous potential, even in a dynamic and unpredictable environment like Dota 2. It gives us a glimpse of how AI could be enabled to optimize their strategies and function at a level comparable to compete with professional players in real-world scenarios.
References
[1] M. Hutson, “AI takes on video games in quest for common sense,” Science, vol. 361, no. 6403, pp. 632–633, 2018.
[2] A. Vieira and B. Ribeiro, Introduction to deep learning business applications for developers: from conversational bots in customer service to medical image processing. Berkeley, California: Apress, 2018.
[3] Bansal, Jakub, Szymon, Ilya, Mordatch, Igor, and Sidor, “Emergent Complexity via Multi-Agent Competition,” [1402.1128] Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition, 14-Mar-2018. [Online]. Available: https:// arxiv.org/abs/1710.03748. [Accessed: Sep-2018].
[4] OpenAI, “OpenAI Five Benchmark: Results,” OpenAI Blog, 31-Aug-2018. [Online]. Available: https://blog.openai.com/openai-five-benchmark-results/. [Accessed: Sep-2018].
[5] W. Knight, “Deep learning boosted AI. Now the next big thing in machine intelligence is coming,” MIT Technology Review, 06-Apr-2017. [Online]. Available: https:// www.technologyreview.com/s/603501/10-breakthrough-technologies-2017-reinforcement-learning/. [Accessed: Sep-2018].


