
Abstract
The board game Go has been viewed as one of the most challenging tasks for artificial intelligence because it is “complex, pattern-based and hard to program”. The computer program AlphaGo’s victory over Lee Sedol became a huge moment in the history of artificial intelligence and computer engineering. We can observe AlphaGo’s enormous capacity, but people know little about how it “thinks”. AlphaGo’s rules are learned and not designed, implementing machine learning as well as several neural networks to create a learning component and become better at Go. Seen in its partnership with the UK’s National Health Service, AlphaGo has promising applications in other realms as well.
Background
From March 9 to March 15 in 2016, a Go game competition took place between the world’s second-highest ranking professional player, Lee Sedol, and AlphaGo, a computer program created by Google’s DeepMind Company. AlphaGo’s 4-1 victory over Lee Sedol became a significant moment in the history of artificial intelligence. This was the first time that a computer had beaten a human professional at Go. Most major South Korean television networks carried the game. In China, 60 million people watched it; the American Go Association and DeepMind’s English-language livestream of it on YouTube had 100,000 viewers. A few hundred members of the press watched the game alongside expert commentators [1]. What makes this game so important? To understand this, we have to understand the roots of Go first.
Go Game
Go, known as weiqi in China and igo in Japan, is an abstract board game for two players that dates back 3,000 years. It is a board game of abstract strategy played across a 19*19 grid. Go starts with an empty board. At each turn, a player places a black or white stone on the board [2]. The general objective of the game is to use the stones to surround more territory than the opponent. Although the rule is very simple, it creates a challenge of depth and nuance. Thus, the board game, Go, has been viewed as one of the most challenging tasks for artificial intelligence because of its complexity and pattern-based state.
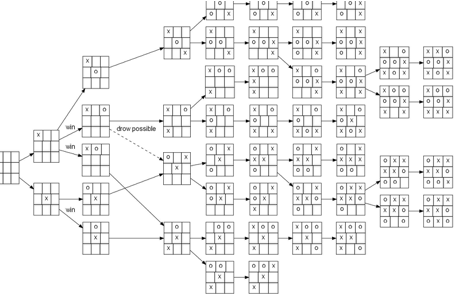
In common computer games, the AI usually uses a game tree to determine the best next move in the game depending on what the opponent might do. A game tree is a directed graph that represents game states (positions) as nodes, and possible moves as edges. The root of the tree represents the state at the beginning of the game. The next level represents the possible states after the subsequent moves [3]. Take the simple game tic-tac-toe as an example, it is possible to represent all possible game states visually in Figure 1 [3].
Figure 1: A complete game tree for tic-tac-toe [3].
However, for complex games like Go, getting the best next move in the game quickly becomes impossible since the game tree for Go will contain 10^761 nodes, an overwhelming amount to store in a computer (the universe has only 10^80 atoms, for reference) [4]. This explains why Go has been viewed as one of the greatest challenges for artificial intelligence for so long. Most AIs for board games use hand-crafted rules created by AI engineers. Since these rules might be incomplete, they usually limit the intelligence of the AI. For example, for a certain stage of Go, the designers think the computer should choose one of ten selected steps, but these might be silly moves for professional players. The Go game level of the designers will influence the intelligence level of the AI.
AlphaGo Algorithm
So how did AlphaGo solve the complexity of Go as well as the restriction imposed by the game level of the designers? All previous methods for Go-playing AI relied on some kind of game tree search, combined with hand-crafted rules. AlphaGo, however, makes extensive use of machine learning to avoid using hand-crafted rules and improve efficiency. Machine learning is a type of artificial intelligence that provides computers with the ability to learn without being explicitly programmed. Machine learning focuses on the development of computer programs that can teach themselves to grow and change when exposed to new data. The machine learning systems search through data to look for patterns. But instead of extracting data for human comprehension — as is the case in data mining applications — it uses the data to detect patterns and adjust program actions accordingly [4]. AlphaGo also uses deep learning and neural networks to teach itself to play. Just like iPhotos is able to help you divide photos into different albums according to different characters because it holds the storage of countless character images that have been processed down to the pixel level, AlphaGo’s intelligence is based on it having been shown millions of Go positions and moves from human-played games.
AlphaGo’s intelligence relies on two different components: a game tree search procedure and neural networks that simplify the tree search procedure. The tree search procedure can be regarded as a brute-force approach, whereas the convolutional networks provide a level of intuition to the game-play [5]. The neural networks are conceptually similar to the evaluation function in other AIs, except that AlphaGo’s are learned and not designed, thus solving the problem of the game level of the designers influencing the intelligence level of AI.
Neural Networks
Generally, two main kinds of neural networks inside AlphaGo are trained: policy network and value network. Both types of networks take the current game state as input and grade each possible next move through different formulas and output the probability of a win. On one side, the value network provides an estimate of the value of the current state of the game: what is the probability of the black player to ultimately win the game, given the current state? The output of the value network is the probability of a win. On the other side, the policy networks provide guidance regarding which action to choose, given the current state of the game. The output is a probability value for each possible legal move (the output of the network is as large as the board). Actions (moves) with higher probability values correspond to actions that have a higher chance of leading to a win. One of the most important aspects of AlphaGo is learning-ability. Deep learning allows AlphaGo to continually improve its intelligence by playing a large number of games against itself. This trains the policy network to help AlphaGo predict the next moves, which in turn trains the value network to ascertain and evaluate those positions [5]. AlphaGo looks ahead at possible moves and permutations, going through various eventualities before selecting the one it deems most likely to succeed.
In general, the combined two neural networks let AlphaGo avoid doing excess work: the policy network focuses on the present and decides the next step to save time on searching the entire game tree, and the value network focuses on the long run, analyzing the whole situation to reduce possible moves in the game tree. AlphaGo then averages the suggestion from two networks to make a final decision. What makes AlphaGo so important is that it not only follows the game theory but also involves a learning component. By playing against itself, AlphaGo automatically became better and better at Go.
Future of AlphaGo
The Go games were fascinating, but more important is AlphaGo’s demonstration of the ways artificial intelligence algorithms will affect our lives; AI will make humans better. In the 37th move in the second game, AlphaGo made a very surprising decision. A European Go champion said “It’s not a human move. I’ve never seen a human play this move. So beautiful.” This European Go champion who helped teach AlphaGo by playing against it said that though he lost almost all the games, his understanding of Go was greatly improved due to the unusual way the program played. This was also reflected by his jump in world rankings [6].
According to the data, in the United States, there are around 40,500 patients that die of misdiagnosis. The amount of medical information available is huge, so it is impossible for doctors to sort through every little thing. AIs like AlphaGo are able to collect all the medical literature history as well as medical cases, medical images, and other data in the system, and can output the best solution to help doctors. Recently, AlphaGo launched a partnership with the UK’s National Health Service to improve the process of delivering care with digital solutions. AlphaGo uses its computing power to analyze health data and records. [6] This will open up new treatment opportunities to patients and assist physicians in treating patients. The increased efficiency will also reduce costs for insurance companies [6].
Future of AI
People already learn so much from the best humans, but now even more knowledge can be acquired from AI. [6] Artificial intelligence can surpass human capabilities in certain situations, and this may make some people uncomfortable. Artificial intelligence uses many techniques in addition to the board game artificial intelligence represented by AlphaGo, with a variety of technical fields including visual recognition and voice recognition. The fact that AI can outperform humans in a specialized area is not surprising. However, in comprehensive intelligence and learning ability, humans are much better than AIs. Although deep learning has made a lot of progress, machine learning still relies on a manual design progress. Moreover, deep learning requires a large amount of data as a basis for training and learning, and the learning process is not flexible enough.
The idea that a comprehensive artificial intelligence will control humans and will have a devastating impact on human society is fictitious. It is not impossible that AI will go beyond human, but that day is still far away, and the “beyond” will still be under human control.
Conclusion
Whether it is AlphaGo or Lee Sedol winning, overall the victory lies with humankind. The AI behind AlphaGo uses machine learning and neural networks to allow itself to continually improve its skills by playing against itself. This technique of artificial intelligence also offers potential for bettering our lives.
The AI won the Go game, but the human won the future.
References
[1] “How Google’s AlphaGo Beat a Go World Champion” The Atlantic. Web. 28 Mar. 2016 <http://www.theatlantic.com/technology/archive/2016/03/the-invisible- opponent/475611/>
[2] “Go (game)” The Wikipedia. Web. <https://en.wikipedia.org/wiki/Go_(game)>
[3] “Game Tree” The Wikipedia. Web. <https://en.wikipedia.org/wiki/Game_tree>
[4] “Definition machine learning” The WhatIs. Web. Feb. 2016 <http://whatis.techtarget.com/definition/machine-learning?
[5] “Google DeepMind’s AlphaGo: How it works” The tastehit. Web. 16 Mar. 2016 <https://www.tastehit.com/blog/google-deepmind-alphago-how-it-works/>
[6] “AlphaGo Can Shape the Future of Healthcare” The TMF. Web. 5 April. 2016 <http://whatis.techtarget.com/definition/machine-learning>


