Modern music recognition software has taken the guesswork out of locating music. With just a tap of a finger, smartphone users everywhere can record, send, and analyze 15 seconds worth of music to receive a response with the track name in only a matter of seconds. By analyzing a song’s unique “audio fingerprint” and reducing the necessary amount of identifying information, the song in question can be matched within a database in increasingly short periods of time, made possible by a powerful algorithm developed by engineers. Now, no territory is unfamiliar for the music connoisseur; any song, anywhere, can now be identified by its correct name and downloaded in a few short steps.
Introduction
Every so often in the engineering world, a product comes along that makes life easier—it takes the “manual” out of manual labor, puts the “automatic” in automatic transmission, or adds the “instant” in instant search. For music lovers, the last decade of engineering developments has transformed the way people listen to and purchase music: mp3 players, peer-to-peer downloading software, online music stores, and music recommendation programs were birthed out of the iPod generation. But something new has arrived that has made searching for tunes ever so harmonious.
No longer do head-bobbing passengers in the back seat of their friend’s car need to wonder what great new song that they’ve never heard before is blasting on the radio; never again will listeners at a bar have to scramble to write down the lyrics on their hands, so they can post it into a search engine later hoping to strike gold; and never again will great music go unrecognized and unsold—because now, there’s an app for that, and it’s called music recognition software.
Deciphering the Music Recognition Dilemma
When developers and entrepreneurs began to tackle the music recognition problem, many told them that their chances for finding a quick fix were slim. Surely, the sheer volume of music on the market and speed with which songs could be compared with one another would require considerable space to house servers and countless hours to search those servers. Yes, one could compare the audio signatures of every song, which had been done for years; but trying to compare the frequency vs. time graph (a scattered map of the sound’s electronic waves over time) of two million files was by no means going to be instantaneous. This matching game was evolving into a puzzle that might call for nearly ten years of research and plenty of exhausted funds in order to produce only an unfinished product. Yet, researchers played stubborn and businessmen refused to say no, and a product was born that exceeded all expectations.
The Audio Fingerprint
All sound files have a unique audio signature, or fingerprint. A graph of their frequency and amplitude versus time displays a complex wave that is exclusive to every song (see Fig. 1). At the time, the most effective way to compare two sound files was to stand them side by side and progressively check each time frame for a match. This worked well enough when the library where the database files were stored was small. However, when a user wanted the name for the song in his or her favorite 1988 B-movie that raked in only 200 downloads last month on iTunes, an issue arose.
That is when developers took a radically different approach—they decided to output as much information about a song as possible. In essence, they wanted to rid the audio file of the majority of the very information that had been used before to analyze and compare it. Soon, 3 megabyte files were being whittled down to 64 bytes of information. Hours of searching using older algorithms was soon replaced by a version 10,000 times faster. With a new 2-dimensional approach to music signature analysis, an effective algorithm was devised, and it required 50,000 times less information [1].
25 Seconds on a Mobile Phone
When a user accesses music recognition software databases, there is more than just an effective search algorithm at work. The network and procedure for receiving that golden transmission that puts the satisfaction on the face of the curious music connoisseur takes form in an intuitive and streamlined process of user messaging and database response. Before smart phones existed, music recognition software developers like Shazam relied on alternative methods for data transfer, the first of which was called the “2580 Service” [2].
At the time, the customer would dial the 2580 shortcode, connecting a call with the automated system at the database headquarters. With music humming along in the background, computers would record 15 seconds of audio in order to capture a portion of the track’s acoustic fingerprint. After analysis using the unique search algorithm, the customer would receive an SMS message carrying the name of the intended song. If the service was successful—which, when it did provide a response, it was 999,997 out of 1,000,000 times—a small charge would be billed to their account [3].
When smart phones hit the market, music recognition software developers were quick to jump on the bandwagon—they realized the easy transition for their service into the world of mobile applications, and many of them even dropped the service charge and replaced revenue with banner advertisements. With just a click, an aim of the phone at the audio source, a few seconds of listening, and a few more moments waiting for a response, modern users can now receive not only the name of the track being played but also some basic information about the file complete with album cover art.
In a matter of roughly 25 seconds, this valuable information is placed firmly in the user’s hand. In only a few more seconds, users can make a quick click on a download button and be transferred to an online music store to download the song instantaneously to their phone.
The Secret is in the Algorithm
But what is it about modern music recognition software that makes it so effective? The answer lies almost wholly in the search and comparison algorithm. When the audio tracks are trimmed down to a light 64 byte package, not all information about the song’s acoustic signature is being thrown out—the database files still contain “hashes” of audio information designating peaks and troughs of relative amplitude maxima and minima (the most extreme points of intensity in the sound wave). As mentioned before, the time-frequency graph of a song’s audio fingerprint displays the highs, lows, and everything in between of the entire file’s amplitude, frequency, and time. When chopping away at much of this data, the developers decided that keeping the highest peaks and lowest troughs in progressive small segments of audio would provide the quickest and easiest way to discern one track from another.
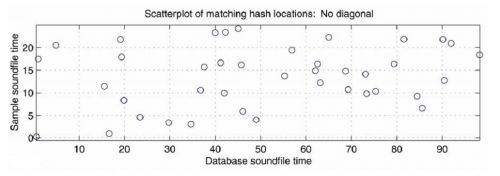
With a circle placed on a basic x-y coordinate grid for every maxima and minima in amplitude, the scatter plot of the song’s hashes begins to look much like a constellation chart (see Fig. 2).
It is easy to see that in comparison to the dense, overwhelming picture drawn by a full audio fingerprint, the hashed sound file is much simpler. In addition, the hashed file has an additional practical benefit: by allocating plot points to only the most extreme amplitudes in small audio segments, a vast majority of outside noise and distortion is discarded. This is often referred to as robustness [1].
Fast Combinatorial Hashing
With thousands of times less memory space occupied than a full audio file and the ability to ignore much of the ambient, external, and dubbed noise accustomed with a file recorded from a radio, a bar atmosphere, or a movie, music recognition software developers were soon on track to revolutionizing their field. Their next dilemma was to compare their new hashed audio signatures efficiently and effectively.
Even after the great reduction in data from each track, there were still millions of hashes present in the databases that would need to be compared. At this point, the developers created a way to differentiate these hashes even further: it was called fast combinatorial hashing [1].
In fast combinatorial hashing, anchor points are chosen on each constellation map, signifying a centralized peak or trough to be encircled by a target zone. The target zone is an area of the constellation map with a predetermined space based upon time multiplied by amplitude. Within the target zone, all other hash points that are present are measured from the anchor point. In other words, the program creates a type of matrix in which the distance between each anchor point and target zone pair makes the hash even more unique and discernible. Distance, created by time and frequency, is added to the equation.
Searching and Sorting More Efficiently
As Shazam lead developer Avery Wang put it, “By forming pairs instead of searching for matches against individual constellation points, we gain a tremendous acceleration in the search process” [1]. The probability of having constellation points at the same frequency was already very small, but with the introduction of anchor points and target zones the process underwent a “tremendous amount of speedup” [1]. To complete the process, the music recognition software simply searches and compares the now hashed-out audio files.
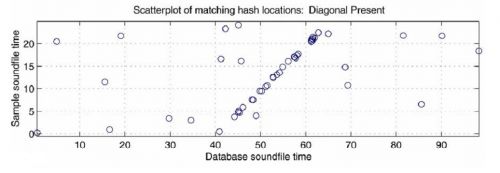
Sorting is accomplished by placing the hashes of songs into bins: time pairs with similar offset times are segregated accordingly and marked by their track ID numbers. When the user sends an audio file to the database, it is broken down into hashes and then designated for search in the corresponding bin. From here, comparison of the tracks is relatively simple and can be imagined as follows: the user’s recorded track is printed as a hashed constellation map, complete with time pairs, on a clear plastic projector sheet. The database files, printed in the same manner but on opaque white pieces of paper, are laid underneath the clear plastic “token” sheet. The token sheet slides over each database file until it finds a match—when it superimposes the same constellation points in an overlapping diagonal line [3].
Even if the sound file sent from the user’s phone may be far along in the audio track, and even if its ten millisecond hashes may not perfectly overlay the entirety of the database hash, any high percentage match of the two is enough to provide assurance that the two tracks are the same. This is also the beauty of the algorithm. Only the time pairs need to match up—the system does not need to check every sequential point, a solution that would have likely taken minutes to return.
Surpassing All Expectations
With the goal of providing an efficient music recognition program at a low cost, the developers of these software packages were quite successful. They measured their performance in terms of noise resistance, speed, specificity, and false positives. Amazingly, they asserted: “To give an idea of the power of this technique, from a heavily corrupted 15 second sample, a statistically significant match can be determined with only about 1-2% of the generated hash tokens actually surviving and contributing to the offset cluster” [1]. Even more impressively, “is that even with a large database, [they] can correctly identify each of several tracks mixed together, including multiple versions of the same piece, a property [they] call ‘transparency'” [1].
The sheer conclusiveness of the numbers produced by analyzing this algorithm puts many doubters to shame—“[on a single PC database of] 20,000 tracks, the search time is on the order of 5-500 milliseconds” (Wang). A task once presumed to require full buildings worth of servers and lengthy amounts of time was diminished to a few dozen PCs and tenths of a second. Because of the complexity of the algorithm and the way it breaks down music quantitatively, “given a multitude of different performances of the same song by an artist, the algorithm can pick the correct one even if they are virtually indistinguishable by the human ear” [1].
And lastly, the developers set out to determine the frequency of occurrence of false positives, to which Wang surmised “that the probability of finding a false match is less than three in a million” [3]. Along the way, they also “anecdotally discovered several artists in concert who apparently either have extremely accurate and reproducible timing (with millisecond precision), or are more plausibly lip synching” [1].
Measuring the Effects
It is easy to see how such a well-thought out algorithm can provide amazingly effective results, leading to even more unintended user benefits. Never again will you have to wonder what interesting new song your neighbor is playing through the walls, nor will you have to worry about the muddled distortion caused by the barrier between yourself and their speakers. Never again will music providers have to worry that so many of their songs will go unsold because no one will be able to locate the track’s name online. From now on, concert artists will have to be wary of their smart phone-wielding audience that can blow the cover on their lip synching tricks with a press of a button and the use of music recognition software.
Perhaps music recognition software has not revolutionized the world, but it has added to the joy of living for music fans across the globe. After all, who doesn’t want to know what song they are listening to?